Data Cleaning - Dealing with Outliers#
An important first step in data science is cleaning up your data. This includes identifying and removing data points that may be due to errors in data collection, or other factors that could lead us to make erroneous conclusions about the data. This is not the same as “cooking” your data — modifying it specifically to get the results you want. Data cleaning involves a set of methods that are specifically designed to identify and remove data points that are objectively anomalous — that is, you have objective reasons for removing them. Data cleaning steps should always be documented when you write up a study, and should be included in the code you share for analyses so that your procedures are transparent and reproducible.
Outlier Identification and Removal#
Outliers are data points that are “significantly different” from the majority of data points in a data set. “Significantly different” is in quotes here, because this doesn’t not necessarily mean we use statistical testing to define outliers, and also that there several different definitions of “significant” that ca be used to identify outliers.
Tukey’s method#
John Tukey, who was a driving force in the development of exploratory data analysis, defined outliers as points more than \(1.5 x IQR\). Recall that IQR is the inter-quartile range, which captures 50% of the data points in a data set. In a box plot (which Tukey invented), the IQR is the “box”, and 1.5 IQR are the extent of the “whiskers” in each direction from the median. We noted earlier that in box plots, outliers are represented as individual points in the plot, beyond the whiskers. Since Tukey invented box plots and this definition of outliers, it’s not surprising that they are identical. In general, outliers defined in this way will comprise approximately 1% of the data, if the data are approximately normally distributed.

Image from Jhguch and shared under the Creative Commons Attribution-Share Alike 2.5 Generic license, via Wikimedia Commons
Standard scores#
An alternative method is to use standard scores. This is done by applying the z transform to the data. This transform’s formula is:
$z = \frac{x - \mu}{\sigma}$
Where \(x\) is an individual data point, \(\mu\) is the mean of the data set, and \(\sigma\) is the standard deviation. In other words, the z transform takes a data set and transforms it so that its mean is zero (by subtracting the mean from every value), and its standard deviation as 1.
Put another way, after we apply a z transform to a data set, the numerical values in the data set are not in their original units (be that milliseconds, or dollars, or whatever) but in units of standard deviations. So in a z transformed data set, a data point with a value of 1 would have had an original value that was 1 standard deviation from the mean. This is where the “standard” in “standard scores” comes from.
Applying a z transform is also called normalizing the data set, because the z transform assumes that the data come from a normal distribution (also known as a Gaussian distribution, or the bell curve). The nice thing about standardizing a data set is that the values have fairly straightforward interpretations. In a normal distribution:
68.27% of all values fall within ±1 standard deviation of the mean (\(1 \sigma\)),
95.45% of all values fall within ±2 standard deviations of the mean (\(2 \sigma\)), and
99.73% of all values fall within ±3 standard deviations of the mean (\(3 \sigma\))

Image from M. W. Toews, and shared under the Creative Commons Attribution-Share Alike 2.5 Generic license, via Wikimedia Commons
{kind=link}
This means that if we define outliers as those values z > 3 or z < -3, then we will tend to reject about 0.25% of a data set. Sometimes, z ±2.5 \(\sigma\) is used instead. This will tend to reject more data points (typically around 2%).
Identifying outliers#
First, we’ll load in the same Flanker data set we used in the Repeated Measures lesson:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('data/flanker_rt_data.csv')
Visualizing the distribution#
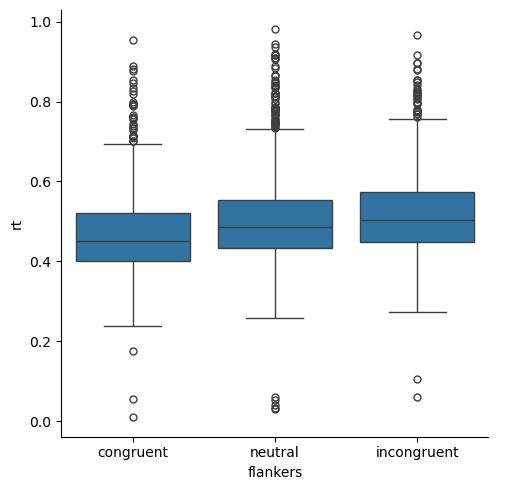
Let’s generate a box plot of the entire data set, organized by condition. This is the same as the first box plot in the Repeated Measures lesson.
sns.catplot(kind='box',
data=df,
x='flankers', y='rt')
plt.show()
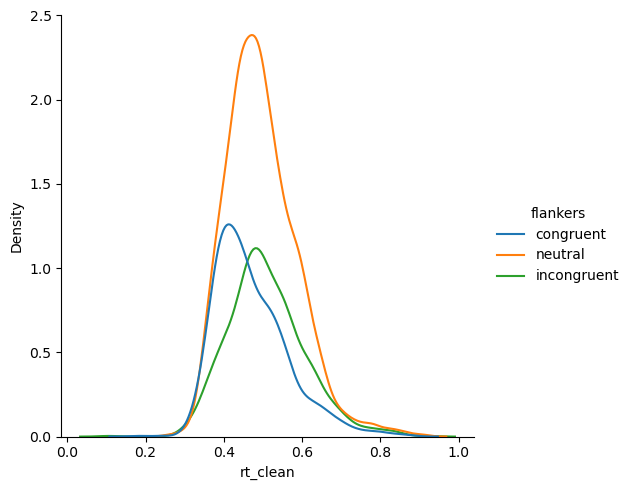
Let’s also look at the distribution of values with a kernel density estimate:
sns.displot(kind='kde',
data=df,
x='rt', hue='flankers')
plt.show()
Idenfity outliers in a DataFrame#
To define values based on the IQR, we first need to calculate the IQR. pandas doesn’t have a method for this specifically, but we can use the pandas .quantile() method with the argument 0.25 to reference the lower end of the IQR (the 0.25 quantile means the point below which 25% of data values lie), and 0.75 for the upper end of the IQR. Since IQR is defined as the range between the 25th and 75th quantiles, we can compute it be subtracting the difference between the two:
q1 = df['rt'].quantile(0.25)
q3 = df['rt'].quantile(0.75)
iqr = q3 - q1
The variable iqr represents the size of the box in the box plot of the data. Recall that our definition of outliers is 1.5 x IQR — the length of the whiskers in the box plot.
We can now define the threshold for values we well call “outliers” (i.e., the length of the whiskers) based on iqr:””
out_low = q1 - 1.5 * iqr
out_high = q3 + 1.5 * iqr
So out_low (the end of the bottom whisker) is 1.5 x IQR below q1 (the lower end of the box), and likewise for out_high.
Recall from the pandas lesson that we can select values in a DataFrame using a Boolean mask. We can do that here to identify the rows of the DataFrame where the RT values are lower than 1.5 x IQR:
df.loc[:, 'rt'] < out_low
0 False
1 False
2 False
3 False
4 False
...
4284 False
4285 False
4286 False
4287 False
4288 False
Name: rt, Length: 4289, dtype: bool
The result will have values of True for those data points that are “low” outliers, and False for all other data points. We can count the number of these by passing the mask to np.sum() (since True = 1 and False = 0)
np.sum(df.loc[:, 'rt'] < out_low)
np.int64(10)
We can do the same to identify outliers at the high end of the range of values, using the > operator this time:
np.sum(df.loc[:, 'rt'] > out_high)
np.int64(110)
Consistent with what we saw in the box plot, there are more outliers at the high (slow RT) end of the distribution than at the low (fast RT) end.
Marking data points as outliers#
We’ll worry about what to do with outliers later — after we’ve described standard scores. For now, let’s make a column in df called outliers_tukey that is a Boolean mask: values of True in rows with outlier RT values, and False for all other rows.
To do this, we want to combine the two masking operations above < out_low and > out_high. We can do that using the OR | operator, as long as we include each of our masking operations in parentheses (this last bit is important, but easy to forget!):
(df.loc[:, 'rt'] < out_low) | (df.loc[:, 'rt'] > out_high)
0 False
1 False
2 False
3 False
4 False
...
4284 False
4285 False
4286 False
4287 False
4288 True
Name: rt, Length: 4289, dtype: bool
It’s a bit hard to confirm that this works from the output above, but if we pass that whole expression to np.sum() we can see that the number of all True values is the same as the total of the out_low and out_high values reported above:
np.sum((df.loc[:, 'rt'] < out_low) | (df.loc[:, 'rt'] > out_high))
np.int64(120)
To actually use this expression to create a new column, we just have to assign the result to a new column name in df:
df['outliers_tukey'] = (df.loc[:, 'rt'] < out_low) | (df.loc[:, 'rt'] > out_high)
df.head()
| participant | block | trial | flankers | rt | outliers_tukey | |
|---|---|---|---|---|---|---|
| 0 | s25 | 1 | 1 | congruent | 0.652072 | False |
| 1 | s25 | 1 | 2 | neutral | 0.644872 | False |
| 2 | s25 | 1 | 3 | congruent | 0.445182 | False |
| 3 | s25 | 1 | 4 | neutral | 0.525200 | False |
| 4 | s25 | 1 | 5 | congruent | 0.533328 | False |
And double-check the number, using the pandas .sum() method:
df['outliers_tukey'].sum()
np.int64(120)
Standard scores (z transform)#
We can convert scores to standard scores very easily, using the zscore() function in scipy.stats:
from scipy import stats
df['rt_z'] = stats.zscore(df['rt'])
df.head()
| participant | block | trial | flankers | rt | outliers_tukey | rt_z | |
|---|---|---|---|---|---|---|---|
| 0 | s25 | 1 | 1 | congruent | 0.652072 | False | 1.526800 |
| 1 | s25 | 1 | 2 | neutral | 0.644872 | False | 1.456483 |
| 2 | s25 | 1 | 3 | congruent | 0.445182 | False | -0.493736 |
| 3 | s25 | 1 | 4 | neutral | 0.525200 | False | 0.287737 |
| 4 | s25 | 1 | 5 | congruent | 0.533328 | False | 0.367119 |
Now we can identify outliers as those rows where rt_z > 2.5 or rt_z < -2.5. We’ll define a variable z_thresh because that way we can later change it to a different value (like 3) if we desire.
z_thresh = 2.5
(df['rt_z'] > z_thresh) | (df['rt_z'] < z_thresh)
0 True
1 True
2 True
3 True
4 True
...
4284 True
4285 True
4286 True
4287 True
4288 True
Name: rt_z, Length: 4289, dtype: bool
More simply, we can take the absolute value of z (which ignores the - sign):
np.abs(df['rt_z']) > z_thresh
0 False
1 False
2 False
3 False
4 False
...
4284 False
4285 False
4286 False
4287 False
4288 True
Name: rt_z, Length: 4289, dtype: bool
The number of outliers identified this way is:
np.sum(np.abs(df['rt_z']) > z_thresh)
np.int64(111)
You’ll note that there are actually fewer outliers defined this way as using the 1.5 x IQR (Tukey) method. Why is this? As noted earlier, Tukey’s threshold and z >= 2.5 are only approximately the same, so we expect minor differences. However, we noted that the 1.5 x IQR range is a bit wider than z > 2.5, meaning it should capture more data points and fewer values should be identified as outliers by Tukey’s method. Yet yere, more are. The reason for this is that both Tukey’s and the standard score methods assume our data are normally distributed, when in fact they are skewed, with more values at the high (slow RT) end than at the low (fast RT) end. Since the data don’t fit the assumptions of the methods we used, we get unexpected results.
Write column of standard score outliers#
We’ll worry about skewness a little later, but for now we will add a column marking outliers as defined this way, similarly to what we did above for the Tukey method:
df['outliers_z'] = np.abs(df['rt_z']) > z_thresh
df.sample(6)
| participant | block | trial | flankers | rt | outliers_tukey | rt_z | outliers_z | |
|---|---|---|---|---|---|---|---|---|
| 4266 | s15 | 5 | 10 | congruent | 0.469193 | False | -0.259240 | False |
| 388 | s16 | 3 | 5 | incongruent | 0.466236 | False | -0.288120 | False |
| 2438 | s14 | 2 | 29 | neutral | 0.552982 | False | 0.559062 | False |
| 4199 | s15 | 3 | 7 | neutral | 0.553530 | False | 0.564415 | False |
| 3546 | s20 | 2 | 23 | neutral | 0.506039 | False | 0.100608 | False |
| 3231 | s27 | 2 | 25 | neutral | 0.486164 | False | -0.093496 | False |
The above .sample() is not likely to happen to sample outlier data points, but we can confirm their presence with:
df[df['outliers_z'] == True]
| participant | block | trial | flankers | rt | outliers_tukey | rt_z | outliers_z | |
|---|---|---|---|---|---|---|---|---|
| 26 | s25 | 1 | 27 | incongruent | 0.757437 | True | 2.555820 | True |
| 37 | s25 | 2 | 6 | neutral | 0.917223 | True | 4.116328 | True |
| 117 | s25 | 4 | 22 | incongruent | 0.817285 | True | 3.140311 | True |
| 227 | s18 | 3 | 4 | neutral | 0.806528 | True | 3.035256 | True |
| 350 | s16 | 1 | 32 | incongruent | 0.762060 | True | 2.600971 | True |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4208 | s15 | 3 | 16 | incongruent | 0.897641 | True | 3.925088 | True |
| 4231 | s15 | 4 | 7 | congruent | 0.881503 | True | 3.767480 | True |
| 4262 | s15 | 5 | 6 | incongruent | 0.853477 | True | 3.493770 | True |
| 4279 | s15 | 5 | 23 | neutral | 0.845636 | True | 3.417194 | True |
| 4288 | s15 | 5 | 32 | congruent | 0.789597 | True | 2.869903 | True |
111 rows × 8 columns
Why are outliers a problem?#
Outliers are a problem because they have disproportionate leverage on statistical properties of the data, such as the mean and variance. We can see this by creating a small, simulated data set from a normal distribution, then replacing one value with either an extremely different or just slightly different data point. Let’s do this, and compare the means and standard deviations in each case. We use NumPy’s np.random.default_rng().normal() function to do this:
# Create array with mean=0, standard deviation=1, and 10 data values
data = np.random.default_rng().normal(0, 1, 10)
print("Data:", str(data))
print("Mean of data with no outliers:", str(round(np.mean(data), 5)))
print("Standard deviation of data with no outliers:", str(round(np.std(data), 5)))
Data: [-2.24169094 0.80619082 1.24266227 -0.26668543 -0.04420904 0.75974712
0.40870655 -0.97212501 0.40320117 -0.06681444]
Mean of data with no outliers: 0.0029
Standard deviation of data with no outliers: 0.95649
data_not_extreme = np.copy(data)
# replace last value in array with outlier
data_not_extreme[-1] = 3
print("Data:", str(data_not_extreme))
print("Mean of data with minor outlier:", str(round(np.mean(data_not_extreme), 5)))
print("Standard deviation of data with minor outlier:", str(round(np.std(data_not_extreme), 5)))
Data: [-2.24169094 0.80619082 1.24266227 -0.26668543 -0.04420904 0.75974712
0.40870655 -0.97212501 0.40320117 3. ]
Mean of data with minor outlier: 0.30958
Standard deviation of data with minor outlier: 1.31095
data_extreme = np.copy(data)
# replace last value in array with outlier
data_extreme[-1] = 10
print("Data:", str(data_extreme))
print("Mean of data with extreme outlier:", str(round(np.mean(data_extreme), 5)))
print("Standard deviation of data with extreme outlier:", str(round(np.std(data_extreme), 5)))
Data: [-2.24169094 0.80619082 1.24266227 -0.26668543 -0.04420904 0.75974712
0.40870655 -0.97212501 0.40320117 10. ]
Mean of data with extreme outlier: 1.00958
Standard deviation of data with extreme outlier: 3.14566
From the above we can see that a larger outlier has a larger impact on both the mean and variance of the data. Also remember, when looking at the information above, that the true population mean of the data (as specified in the arguments to the random number generator) is 0 and the true standard deviation is 1. Using this normal distribution makes it easy to see that outliers bias our statistics away from the true population mean and variance.
The impact of outliers is often less extreme — in the above examples, our data set comprised only 10 values, and so making one an outlier meant that 10% of data points were outliers — whereas by the definitions above, we would normally expect only 1–2% of data points to be outliers.
If we re-run the simulations with a data set of 100 values and one outlier, you can see that the impact of even an extreme outlier is much reduced:
# Create array with mean=0, standard deviation=1, and 10 data values
data = np.random.default_rng().normal(0, 1, 100)
print("Data:", str(data))
print("Mean of data with no outliers:", str(round(np.mean(data), 5)))
print("Standard deviation of data with no outliers:", str(round(np.std(data), 5)))
Data: [-0.55217689 2.38388882 -0.14448226 -0.63466719 -0.53388823 -1.21193743
0.28520992 -0.3510115 1.70062189 -1.51565004 1.53536507 -0.40226561
0.10075665 -1.18449857 -0.86304433 1.900511 0.71200058 -0.54642778
-0.13304801 -0.64676967 -0.82921859 -0.44915008 1.20757979 -0.46261846
-0.81559358 0.36913829 0.684389 -1.83963108 0.97289765 -1.73891585
0.26401876 0.05471365 -2.20375297 0.36721077 -0.26313454 -0.74803455
0.36898695 0.1103685 1.36332798 1.00234393 0.27987849 -0.51961679
-0.54601683 0.65194085 0.21434913 -0.35331688 -0.13808728 0.48420852
-0.02995916 0.40968225 0.57344415 -0.50591486 -0.93366804 -0.16798449
-0.21191812 -1.22902981 0.34667379 0.35947425 -0.38319178 -1.24027628
-1.36038353 0.12286509 -0.66247681 0.95275678 0.69668224 1.62152088
-1.30318278 0.09021245 -0.60383758 -1.1203467 -1.3593154 1.73301811
-0.82430903 -1.22933276 -0.35049609 -1.69888089 -0.03935835 0.49307094
0.49555595 0.89036469 -0.39087918 -1.27431151 1.38792735 -1.74929821
-0.04340761 -1.04585566 0.42386498 1.94063937 -0.01470179 0.66038406
-0.06977182 0.94013885 1.2446099 -0.94255174 -0.93300766 1.7805017
1.02601987 -0.13933979 0.58306756 1.32621834]
Mean of data with no outliers: -0.04372
Standard deviation of data with no outliers: 0.96537
data_extreme = np.copy(data)
# replace last value in array with outlier
data_extreme[-1] = 10
print("Data:", str(data_extreme))
print("Mean of data with extreme outlier:", str(round(np.mean(data_extreme), 5)))
print("Standard deviation of data with extreme outlier:", str(round(np.std(data_extreme), 5)))
Data: [-0.55217689 2.38388882 -0.14448226 -0.63466719 -0.53388823 -1.21193743
0.28520992 -0.3510115 1.70062189 -1.51565004 1.53536507 -0.40226561
0.10075665 -1.18449857 -0.86304433 1.900511 0.71200058 -0.54642778
-0.13304801 -0.64676967 -0.82921859 -0.44915008 1.20757979 -0.46261846
-0.81559358 0.36913829 0.684389 -1.83963108 0.97289765 -1.73891585
0.26401876 0.05471365 -2.20375297 0.36721077 -0.26313454 -0.74803455
0.36898695 0.1103685 1.36332798 1.00234393 0.27987849 -0.51961679
-0.54601683 0.65194085 0.21434913 -0.35331688 -0.13808728 0.48420852
-0.02995916 0.40968225 0.57344415 -0.50591486 -0.93366804 -0.16798449
-0.21191812 -1.22902981 0.34667379 0.35947425 -0.38319178 -1.24027628
-1.36038353 0.12286509 -0.66247681 0.95275678 0.69668224 1.62152088
-1.30318278 0.09021245 -0.60383758 -1.1203467 -1.3593154 1.73301811
-0.82430903 -1.22933276 -0.35049609 -1.69888089 -0.03935835 0.49307094
0.49555595 0.89036469 -0.39087918 -1.27431151 1.38792735 -1.74929821
-0.04340761 -1.04585566 0.42386498 1.94063937 -0.01470179 0.66038406
-0.06977182 0.94013885 1.2446099 -0.94255174 -0.93300766 1.7805017
1.02601987 -0.13933979 0.58306756 10. ]
Mean of data with extreme outlier: 0.04302
Standard deviation of data with extreme outlier: 1.38362
The impact of an individual outlier is thus dependent on the size of the data set, and indeed in many data sets comprising a large number of data points, the impact of one outlier (or even 1% of the data values being outliers) can be quite minimal.
However, the impact of an outlier is also proportionate to its size, relative to the other values in the data set. Here we use 100 as the anomalous value, rather than 10, again in a data set with 100 values:
data_extreme = np.copy(data)
# replace last value in array with outlier
data_extreme[-1] = 100
print("Data:", str(data_extreme))
print("Mean of data with extreme outlier:", str(round(np.mean(data_extreme), 5)))
print("Standard deviation of data with extreme outlier:", str(round(np.std(data_extreme), 5)))
Data: [-5.52176886e-01 2.38388882e+00 -1.44482256e-01 -6.34667194e-01
-5.33888231e-01 -1.21193743e+00 2.85209915e-01 -3.51011498e-01
1.70062189e+00 -1.51565004e+00 1.53536507e+00 -4.02265613e-01
1.00756648e-01 -1.18449857e+00 -8.63044331e-01 1.90051100e+00
7.12000585e-01 -5.46427780e-01 -1.33048014e-01 -6.46769673e-01
-8.29218594e-01 -4.49150080e-01 1.20757979e+00 -4.62618464e-01
-8.15593584e-01 3.69138290e-01 6.84388999e-01 -1.83963108e+00
9.72897654e-01 -1.73891585e+00 2.64018755e-01 5.47136546e-02
-2.20375297e+00 3.67210765e-01 -2.63134537e-01 -7.48034554e-01
3.68986950e-01 1.10368502e-01 1.36332798e+00 1.00234393e+00
2.79878491e-01 -5.19616790e-01 -5.46016829e-01 6.51940847e-01
2.14349130e-01 -3.53316882e-01 -1.38087280e-01 4.84208524e-01
-2.99591562e-02 4.09682248e-01 5.73444146e-01 -5.05914860e-01
-9.33668045e-01 -1.67984489e-01 -2.11918123e-01 -1.22902981e+00
3.46673790e-01 3.59474252e-01 -3.83191784e-01 -1.24027628e+00
-1.36038353e+00 1.22865095e-01 -6.62476809e-01 9.52756779e-01
6.96682240e-01 1.62152088e+00 -1.30318278e+00 9.02124544e-02
-6.03837576e-01 -1.12034670e+00 -1.35931540e+00 1.73301811e+00
-8.24309031e-01 -1.22933276e+00 -3.50496087e-01 -1.69888089e+00
-3.93583484e-02 4.93070939e-01 4.95555945e-01 8.90364692e-01
-3.90879179e-01 -1.27431151e+00 1.38792735e+00 -1.74929821e+00
-4.34076116e-02 -1.04585566e+00 4.23864985e-01 1.94063937e+00
-1.47017891e-02 6.60384055e-01 -6.97718223e-02 9.40138853e-01
1.24460990e+00 -9.42551743e-01 -9.33007661e-01 1.78050170e+00
1.02601987e+00 -1.39339793e-01 5.83067560e-01 1.00000000e+02]
Mean of data with extreme outlier: 0.94302
Standard deviation of data with extreme outlier: 10.00135
Now the impact of this 1% of the data is much more extreme. In some data sets, it is unlikely or even impossible to have very extreme outliers. For example, in the Flanker study we’re working with, the lower bound of RT is 0, and the upper bound is 1000 ms, because if a participant didn’t make a response iwthin 1 s of the stimulus, the trial automatically ended without recording a response. However, in some data sets more extreme values are possible. For example, a technical problem with a neuroimaging system, such as EEG or single-unit recording electrodes, could result in very extreme values relative to normal physiologically-plausible values.
Which method to use?#
If you look at the image idescribing the Tukey method above, you can see that the range of the distribution covered by \(1.5 x IQR\) is just slightly larger than 2.5 \(\sigma\). So, the Tukey method is roughly equivalent to using a z threshold of ±2.5. The \(1.5 x IQR\) range is slightly wider than z = 2.5, and so may on average identify slightly fewer data points as outliers, but the result is probably negligible in practice. However, many researchers use z > 3 as their threshold for outliers, which will tend to identify fewer outliers than the Tukey method.
Since box plots are a great — and well-known — way of visualizing data distributions, there is a logic to using the \(1.5 x IQR\) method to identify outliers since the results will be consistent. However, the approximate equivalence between the Tukey method and z = 2.5 is only true if the data are normally distributed. For skewed data, like RT data, this method may exclude too many outliers. In particular, it will tend to exclude more long RT values than short RT values, even though many of the long RT values are likely valid (especially in a case like the present experiment, where trials were cut off at 1 s, preventing really long RTs).
An empirical study addressing outlier removal with RT data#
Berger and Kiefer (2021) performed a study in which they simulated many samples of reaction times, and introduced either more- or less-extreme outliers into the data. Essentially this was a more sophisticated version of the simulations shown above, and using the natural properties of RT data, and simulating an experiment with different conditions. Berger and Kiefer compared Tukey’s method, the z transform method using thresholds of both 2 and 3, and several other methods, as well as simply leaving outliers in the data. Since this was simulated data, the authors knew the true values of the mean and standard deviation in each data set, which allowed them to compare each method to the “truth” — something we never have the luxury of knowing in experimental psychology and neuroscience.
Berger and Kiefer found that the z transform method was the best choice. With RT data, as noted above, Tukey’s method excluded too many data points on the long-RT side of the distribution. This had two negative impacts: firstly, it made the data appear more normally distributed than it really was, and secondly, it biased the statistical analyses towards false positives (Type 1 errors) — finding statistically significant differences between conditions when they were not present in the “true” data. Berger and Kiefer also observed that not rejecting outliers was the worst choice. The outliers led to a high rate of false negative results (Type 2 errors), meaning that true differences between conditions were not found to be statistically significant, due to the presence of outliers.
The z transform was not perfect (and we cannot expect any method to be), but it was more balanced in not rejecting disproportionately more long RTs than short RTs, rejecting fewer data points overall, and biasing the statistical analyses the least. Since in general, with experimental data we want to only exclude truly anomalous data points, I suggest using a z threshold of 3 for outlier removal. Using a threshold of 2 or 2.5 will naturally exclude more data points, increasing the likelihood that valid data is excluded.
It’s also important to note that trying different outlier removal methods on a real data set, or even different z thresholds to define outliers, introduces a component of researcher bias (or researcher degrees of freedom) into the analysis. Once you start doing this, it because easy to choose a method based on what “looks right” — which is, ultimately, what the researcher thinks the data should look like, not the true nature of the data. For this reason, parameters such as outlier definition method and threshold should be chosen prior to performing the analyses (ideally, preregistering the plan even before running the experiment).
What to do with outliers#
We have three basic options for outliers:
Ignore them — just include them in the data and all analyses
Remove them completely from the DataFrame
Replace them with non-outlier values
1. Ignore them#
Some scientists fundamentally do not believe in rejecting outliers. In working with data from human or animal participants, one can argue that any behavioral response is possibly valid, and outliers may represent interesting data points for any number of reasons (e.g., an exceptionally slow RT may mean the person spent a lot of time thinking about the stimulus and trying to decide on a response).
Another reason to consider not removing outliers (or using some other definition of outliers) is if the data are not actually normally distributed. Indeed, the RT data we have been working with are not normally distributed, they are skewed - an issue which we will address below. Skew is a relatively minor violation of normality. More generally, although the normal distribution is very common in nature, not all data is normally distributed, and so it is worth examining the distribution of your data (one reason we spend so much time looking at box plots, histograms, and other visualizations of distributions).
On the other hand, outliers can arise for reasons that really aren’t of experimental interest (McCormack & Wright, 1964). For instance, in the present data set we have a few very short RTs from true measurement error. In the box plot of the data, we can see 2–3 data points in each flanker condition below 100–200 ms. It is nearly impossible for a typical human to respond to a stimulus in less than this amount of time, particularly when some decision (like which way an arrow is pointing) is required first (Luce, 1991; Whelan, 2008). So rather than being scientifically interesting, these outliers probably reflect trials when the participant accidentally pressed a response button. Likewise, exceptionally long RTs could reflect trials on which the participant thought they pressed the button then realized they didn’t, trials where the participant got distracted, or sneezed and didn’t see the stimulus, etc.. As noted above, Berger and Kiefer (2021) found that not rejecting outliers decreased the likelihood of finding statistically significant differences, when those differences were actually present in the data.
My general advice is not to ignore outliers, unless you have strong, principled reasons as to why outliers might be interesting (or not actually outliers, if the distribution is not normal) and how you would interpret them.
2. Remove them from the data set#
Removing data points — known as trimming or truncation — is acceptable in some cases, but problematic in others. For repeated measures data, it’s often fine to remove outliers at the individual participant level, since we have many other samples of the measurement (i.e., the repeated measures, such as trials). On the other hand, if we only have one measurement for a particular “unit” of the experimental design (e.g., one measurement from each participant, in each condition), then we might not want to completely lose that data point. This is especially true for data that will be analyzed statistically with a t test or ANOVA, because these methods cannot handle missing values.
3. Replace them with non-outlier values#
Another approach to dealing with outliers is to replace them with a less-outlying value. This could be the mean value, or the most extreme value that is not considered an outlier. Replacing an outlier with the mean value basically “neutralizes” that data point, since it is equivalent to the mean it doesn’t alter the mean of the data points. However, it does artificially reduce the variance in the data a bit, because variance is, by definition, the amount by which any data point differs from the mean. But if you are only replacing 1–2% of your data values, the impact on variance should be fairly small. Also note that, properly, the mean that is used as the replacement value should be computed only from all of the non-outlier data values. This is because a major reason to replace or remove outliers in the first place is that they have disproportionate influence on the mean.
Replacing the outlier with the most-extreme non-outlier value will preserve variance contributed by that data point, but reduce the variance relative to retaining the outlier value. Likewise, the impact on the mean will not be neutral, but it will be rather small. Note that an assumption of replacing the outlier value with another, relatively extreme (relative to the mean), value is that the outlier was actually a valid measurement, perhaps with some noise in it. Since we don’t know for sure what the true value of the data was, in principle it seems better to replace outliers with the mean.
Replacing outliers with mean values#
Based on the information above, we will approach outliers in the Flanker data set by applying a z transform, defining outliers as those values with \(\lvert z \lvert \gt 3\), and replace these values with the mean (where the mean is calculated excluding the outlier values).
First, as we did above, we’ll define z_thresh as 3 and fill the outliers_z column with True where \(\lvert z \lvert \gt 3\) and False for all other rows.
z_thresh = 3
df['outliers_z'] = np.abs(df['rt_z']) > z_thresh
Next we’ll create a column containing the mean RT. To exclude the outlier values in computing this, we select only the rows where outliers_z is False:
df['rt_mean'] = df[df['outliers_z'] == False]['rt'].mean()
df.head()
| participant | block | trial | flankers | rt | outliers_tukey | rt_z | outliers_z | rt_mean | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | s25 | 1 | 1 | congruent | 0.652072 | False | 1.526800 | False | 0.49191 |
| 1 | s25 | 1 | 2 | neutral | 0.644872 | False | 1.456483 | False | 0.49191 |
| 2 | s25 | 1 | 3 | congruent | 0.445182 | False | -0.493736 | False | 0.49191 |
| 3 | s25 | 1 | 4 | neutral | 0.525200 | False | 0.287737 | False | 0.49191 |
| 4 | s25 | 1 | 5 | congruent | 0.533328 | False | 0.367119 | False | 0.49191 |
Finally, we fill a new column, rt_clean, with either the original RT value (for non-outliers), or the mean RT (for outliers). The way that we create a new pandas column, contingent on the values of another column, is using the np.where() function. This is essentially a way of running an if-else conditional statement on each row in a pandas column. np.where() takes three arguments, which are (in order), the conditional statement, the value to fill in the new column if the conditional is true, and finally the value to fill in if the conditional is false.
So the code below tests, for each row, whether outliers_z is True. If it is (i.e., an outlier), the mean RT is filled in; otherwise the original RT value for that trial is copied to the clean_rt column. The three arguments to np.where() are each shown on their own line, to make it a little more readable:
df['rt_clean'] = np.where(df['outliers_z'] == True,
df['rt_mean'],
df['rt'])
df.head()
| participant | block | trial | flankers | rt | outliers_tukey | rt_z | outliers_z | rt_mean | rt_clean | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | s25 | 1 | 1 | congruent | 0.652072 | False | 1.526800 | False | 0.49191 | 0.652072 |
| 1 | s25 | 1 | 2 | neutral | 0.644872 | False | 1.456483 | False | 0.49191 | 0.644872 |
| 2 | s25 | 1 | 3 | congruent | 0.445182 | False | -0.493736 | False | 0.49191 | 0.445182 |
| 3 | s25 | 1 | 4 | neutral | 0.525200 | False | 0.287737 | False | 0.49191 | 0.525200 |
| 4 | s25 | 1 | 5 | congruent | 0.533328 | False | 0.367119 | False | 0.49191 | 0.533328 |
Although the first few rows in this DataFrame were not identified as outliers, we can confirm that this procedure worked by filtering the DataFrame to only show us rows where outliers_z is True:
df[df['outliers_z'] == True]
| participant | block | trial | flankers | rt | outliers_tukey | rt_z | outliers_z | rt_mean | rt_clean | |
|---|---|---|---|---|---|---|---|---|---|---|
| 37 | s25 | 2 | 6 | neutral | 0.917223 | True | 4.116328 | True | 0.49191 | 0.49191 |
| 117 | s25 | 4 | 22 | incongruent | 0.817285 | True | 3.140311 | True | 0.49191 | 0.49191 |
| 227 | s18 | 3 | 4 | neutral | 0.806528 | True | 3.035256 | True | 0.49191 | 0.49191 |
| 518 | s22 | 2 | 7 | incongruent | 0.817863 | True | 3.145955 | True | 0.49191 | 0.49191 |
| 841 | s8 | 2 | 11 | congruent | 0.056265 | True | -4.291995 | True | 0.49191 | 0.49191 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4195 | s15 | 3 | 3 | congruent | 0.853705 | True | 3.495996 | True | 0.49191 | 0.49191 |
| 4208 | s15 | 3 | 16 | incongruent | 0.897641 | True | 3.925088 | True | 0.49191 | 0.49191 |
| 4231 | s15 | 4 | 7 | congruent | 0.881503 | True | 3.767480 | True | 0.49191 | 0.49191 |
| 4262 | s15 | 5 | 6 | incongruent | 0.853477 | True | 3.493770 | True | 0.49191 | 0.49191 |
| 4279 | s15 | 5 | 23 | neutral | 0.845636 | True | 3.417194 | True | 0.49191 | 0.49191 |
66 rows × 10 columns
Reporting outlier rejections#
In any report describing your data, you should state:
the method you used to identify outliers
how you dealt with outliers
what proportion of the data were identified as outliers, and thus treated
To get this last value, we can simply compute the number of True values in outliers_z, divided by the total number of trials (rows):
outliers = df['outliers_z'].sum() / df['outliers_z'].count()
# Convert proportion to percent, and round to 2 decimal places
print(str(round(outliers * 100, 2)), "% of the data identified as outliers and replaced with mean value.")
1.54 % of the data identified as outliers and replaced with mean value.
Working with nested data#
All of the above was correct, for data without nesting or repeated measures. The reason for this caveat is that with nested data, what constitutes an “outlier” for one source of data (e.g., one participant) may be a very reasonable value for another person. This is perhaps most intuitive if we think about an experiment comparing older and younger adults. With age, RTs on average get longer. So slow RT that is an outlier for an 18 year old university student may be about the average RT for someone who is 80 years old.
To properly address the nested structure of data in identifying and correcting outliers, we can use the same steps as above, but using the split-apply-combine approach provided by pandas .groupby() method. In other words, we split the data by participant, apply the outlier detection and correction steps, and then combine the data into a new column in the DataFrame.
The code below is probably the most complex that we’ve worked with so far. Take your time going through this, and try to understand it as fully as you can. It may seem like a convoluted series of steps, but they are a logical sequence and each one is optimized for pandas. This is in fact pandas’ suggested approach for outlier correction
Since we’ve added lots of columns above, let’s start fresh by re-loading the DataFrame from the file:
df = pd.read_csv('data/flanker_rt_data.csv')
Compute z scores by participant#
Now let’s split by participant and apply the z transform to the split data. Pandas has a useful method, .transform(), that allows us to run a non-pandas function on a selection from a DataFrame. So we group by participant, select only the rt column to operate on, and then .transform(stats.zscore) and assign this to a new column in the DataFrame, rt_z. Note that when we pass a function to .apply(), we do not put parentheses after the name of the function we are using. That is, if we were running stats.zscore on its own (see above), we would use stats.zscore(df['rt']). But since the we have already selected the data that we are passing with .transform(), we don’t use the parentheses with the function call.
df['rt_z'] = df.groupby('participant')['rt'].transform(stats.zscore)
df.sample(12)
| participant | block | trial | flankers | rt | rt_z | |
|---|---|---|---|---|---|---|
| 69 | s25 | 3 | 6 | neutral | 0.458662 | -0.226504 |
| 399 | s16 | 3 | 16 | incongruent | 0.545684 | 1.030627 |
| 4155 | s15 | 1 | 27 | neutral | 0.573411 | 0.089881 |
| 2525 | s14 | 5 | 20 | incongruent | 0.412353 | -0.547025 |
| 3711 | s17 | 2 | 29 | neutral | 0.658077 | 2.456179 |
| 2238 | s26 | 1 | 20 | neutral | 0.476418 | -0.900013 |
| 2984 | s6 | 4 | 32 | neutral | 0.529100 | 0.438060 |
| 898 | s8 | 4 | 4 | neutral | 0.476252 | 0.122578 |
| 955 | s8 | 5 | 29 | neutral | 0.489256 | 0.227841 |
| 3268 | s27 | 3 | 30 | neutral | 0.490161 | 0.334005 |
| 3818 | s19 | 1 | 9 | congruent | 0.540752 | -0.315447 |
| 2783 | s10 | 3 | 22 | congruent | 0.453672 | -0.513131 |
Compute mean RT from valid trials for each participant#
Likewise, we need to compute the mean RT within participants, so again we could split by participant and then compute the within-participant mean, this time passing np.mean to .transform():
df['rt_mean'] = df.groupby('participant')['rt'].transform(np.mean)
But actually, doing the above computes the mean across all trials for each participant — including the outlier trials. We can compute the mean across only the non-outlier trials by adding a filter on df prior to the groupby operation:
df['rt_mean'] = df[np.abs(df['rt_z']) <= z_thresh].groupby('participant')['rt'].transform(np.mean)
df.head()
/var/folders/nq/chbqhzjx5hb6hfjx708rh2_40000gn/T/ipykernel_48300/4280679880.py:1: FutureWarning: The provided callable <function mean at 0x1157294e0> is currently using SeriesGroupBy.mean. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "mean" instead.
df['rt_mean'] = df[np.abs(df['rt_z']) <= z_thresh].groupby('participant')['rt'].transform(np.mean)
| participant | block | trial | flankers | rt | rt_z | rt_mean | |
|---|---|---|---|---|---|---|---|
| 0 | s25 | 1 | 1 | congruent | 0.652072 | 1.822298 | 0.475143 |
| 1 | s25 | 1 | 2 | neutral | 0.644872 | 1.746028 | 0.475143 |
| 2 | s25 | 1 | 3 | congruent | 0.445182 | -0.369295 | 0.475143 |
| 3 | s25 | 1 | 4 | neutral | 0.525200 | 0.478337 | 0.475143 |
| 4 | s25 | 1 | 5 | congruent | 0.533328 | 0.564439 | 0.475143 |
Fill in mean values for outlier rows#
There’s a catch with this however — since we grouped filtered np.abs(df['rt_z']) <= z_thresh data, this only fills in the non-outlier rows with mean RT, because those are the only rows that get passed to the .transform() method. The mean_RT rows where z exceeds outlier threshold are filled with NaN, since pandas doesn’t know what else to do with them. We can see this if we ask for a sample of just the rows that exceed the outlier threshold:
# view sample of rows to confirm RT varies by participant
df[df['rt_z'] > z_thresh].sample(10)
| participant | block | trial | flankers | rt | rt_z | rt_mean | |
|---|---|---|---|---|---|---|---|
| 322 | s16 | 1 | 3 | incongruent | 0.714257 | 3.013849 | NaN |
| 1525 | s1 | 4 | 1 | neutral | 0.783683 | 4.443189 | NaN |
| 2262 | s26 | 2 | 12 | incongruent | 0.840871 | 3.309630 | NaN |
| 1598 | s13 | 1 | 10 | incongruent | 0.688901 | 3.632997 | NaN |
| 2964 | s6 | 4 | 12 | neutral | 0.917153 | 3.456548 | NaN |
| 609 | s22 | 5 | 2 | incongruent | 0.713883 | 3.328852 | NaN |
| 518 | s22 | 2 | 7 | incongruent | 0.817863 | 4.600506 | NaN |
| 2454 | s14 | 3 | 13 | incongruent | 0.797524 | 5.013169 | NaN |
| 2440 | s14 | 2 | 31 | neutral | 0.701127 | 3.621617 | NaN |
| 1878 | s7 | 5 | 8 | incongruent | 0.965726 | 3.095147 | NaN |
To fix this, we need to group the data by participant again, except this time not excluding outlier rows. Then, we need to replace all NaNs in the rt_mean column with the mean RT for that participant.
To do this, we run another .groupby() + .transform() operation, but this time applying a more complex transformation using a lambda function. Lambda functions are basically a way of writing a small Python function inside a command. They are used when what you need to do is a bit more complex or specific than can be done with an existing method or function.
In this case, what we want to do is group df by participant ID, then fill in the NaN values with the mean RT from all non-NaN values for that participant. We do this by applying two operations in sequence: first we use np.nanmean() to compute the mean over all non-NaN RT values for that participant, and then we pass that value to .fillna() to replace any NaN values for that participant with the mean RT. This works because the x in the lambda function is a variable that refers to the entire grouped data set that we pass to it:
df['rt_mean'] = df.groupby('participant')['rt_mean'].transform(lambda x: x.fillna(np.nanmean(x)))
# Check by again printing a smaple of outlier rows
df[df['rt_z'] > z_thresh].sample(10)
| participant | block | trial | flankers | rt | rt_z | rt_mean | |
|---|---|---|---|---|---|---|---|
| 2579 | s4 | 2 | 10 | incongruent | 0.589781 | 3.158490 | 0.416534 |
| 37 | s25 | 2 | 6 | neutral | 0.917223 | 4.631054 | 0.475143 |
| 2440 | s14 | 2 | 31 | neutral | 0.701127 | 3.621617 | 0.446461 |
| 2016 | s12 | 4 | 20 | neutral | 0.814067 | 3.895140 | 0.490843 |
| 593 | s22 | 4 | 18 | neutral | 0.758045 | 3.868943 | 0.431980 |
| 2314 | s26 | 3 | 32 | neutral | 0.937082 | 4.420926 | 0.550074 |
| 3313 | s27 | 5 | 11 | congruent | 0.832711 | 4.620377 | 0.457454 |
| 3571 | s20 | 3 | 16 | neutral | 0.841455 | 4.189282 | 0.489359 |
| 2964 | s6 | 4 | 12 | neutral | 0.917153 | 3.456548 | 0.466651 |
| 2262 | s26 | 2 | 12 | incongruent | 0.840871 | 3.309630 | 0.550074 |
If you don’t fully understand the lambda function above, that’s OK. It is fairly advanced relative to most of what we’ve covered so far. However, it’s introduced here because it is the proper and efficient way to replace outlier values. It’s also worth knowing about lambda functions because you will start seeing them more in the future!
Create final output column#
Next, we want to create a column called rt_clean that contains the original RT for non-outlier trials, and the mean RT for that participant for outlier trials. We can use np.where() to find outliers and replace them with each individual’s mean RT. Below, we do this in one line of code, which is more compact and efficient than we did above. Earlier, we first created a column, outliers_z and then used that to determine which rows would be filled with the original RT versus the mean RT. However, creating a column in our DataFrame that we will never use again is not efficient use of resources. Here we simply use the threshold test as our conditional.
df['rt_clean'] = np.where(np.abs(df['rt_z']) > z_thresh,
df['rt_mean'],
df['rt'])
df.sample(10)
| participant | block | trial | flankers | rt | rt_z | rt_mean | rt_clean | |
|---|---|---|---|---|---|---|---|---|
| 1014 | s24 | 2 | 25 | neutral | 0.484392 | -1.034175 | 0.581082 | 0.484392 |
| 4135 | s15 | 1 | 7 | neutral | 0.433394 | -1.253653 | 0.557696 | 0.433394 |
| 391 | s16 | 3 | 8 | neutral | 0.542163 | 0.989204 | 0.454536 | 0.542163 |
| 1162 | s21 | 2 | 18 | neutral | 0.538394 | 0.879126 | 0.459101 | 0.538394 |
| 2146 | s9 | 3 | 24 | neutral | 0.385704 | -0.683087 | 0.430409 | 0.385704 |
| 3373 | s3 | 2 | 9 | incongruent | 0.625255 | 0.437515 | 0.580459 | 0.625255 |
| 3191 | s27 | 1 | 17 | neutral | 0.473095 | 0.120456 | 0.457454 | 0.473095 |
| 1896 | s7 | 5 | 28 | neutral | 0.593752 | -0.324925 | 0.626862 | 0.593752 |
| 2227 | s26 | 1 | 9 | incongruent | 0.424844 | -1.495723 | 0.550074 | 0.424844 |
| 4230 | s15 | 4 | 6 | neutral | 0.497183 | -0.641564 | 0.557696 | 0.497183 |
Since a random sample of 10 rows may not show any where z actually exceeded our outlier threshold, we can use filtering to view only those rows where the absolute value of z was greater than our threshold, to confirm that in those rows rt_clean is the same as rt_mean:
df[np.abs(df['rt_z']) > z_thresh].sample(10)
| participant | block | trial | flankers | rt | rt_z | rt_mean | rt_clean | |
|---|---|---|---|---|---|---|---|---|
| 4077 | s5 | 4 | 13 | incongruent | 0.742321 | 3.207646 | 0.499061 | 0.499061 |
| 3058 | s23 | 2 | 10 | congruent | 0.953989 | 3.714217 | 0.542556 | 0.542556 |
| 1878 | s7 | 5 | 8 | incongruent | 0.965726 | 3.095147 | 0.626862 | 0.626862 |
| 851 | s8 | 2 | 21 | neutral | 0.033758 | -3.459308 | 0.477679 | 0.477679 |
| 841 | s8 | 2 | 11 | congruent | 0.056265 | -3.277120 | 0.477679 | 0.477679 |
| 495 | s22 | 1 | 16 | incongruent | 0.722015 | 3.428305 | 0.431980 | 0.431980 |
| 2076 | s9 | 1 | 17 | incongruent | 0.705617 | 3.889038 | 0.430409 | 0.430409 |
| 2579 | s4 | 2 | 10 | incongruent | 0.589781 | 3.158490 | 0.416534 | 0.416534 |
| 667 | s11 | 1 | 28 | incongruent | 0.701472 | 4.127361 | 0.443325 | 0.443325 |
| 609 | s22 | 5 | 2 | incongruent | 0.713883 | 3.328852 | 0.431980 | 0.431980 |
Finally we’ll print out the proportion of data identified as outliers, by computing the number of z values that exceed our threshold, relative to the total number of z values (i.e., the number of rows in the DataFrame):
outliers = df[df['rt_z'] > z_thresh]['rt_z'].count() / df['rt_z'].count()
# Convert proportion to percent, and round to 2 decimal places
print(str(round(outliers * 100, 2)), "% of the data identified as outliers and replaced with mean value.")
1.17 % of the data identified as outliers and replaced with mean value.
Visualizing the cleaned data#
Box plots#
Before outlier correction#
Let’s generate a box plot of the original RT values for reference (this is the same as the one plotted at the top of this lesson).
sns.catplot(kind='box',
data=df,
x='flankers', y='rt')
plt.show()
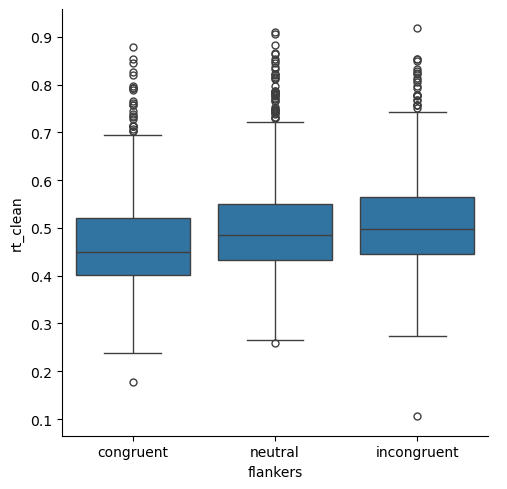
After outlier correction#
Below, we can see that the number of short RT outliers is reduced, and those that remain are very close to the whiskers (and also greater than 200 ms). At the same time, the number of outliers at the long RT end of the distribution is also reduced, but there are still more of them than at the short end (which is reasonable, for RT data).
sns.catplot(kind='box',
data=df,
x='flankers', y='rt_clean')
plt.show()
Kernel density estimates#
Before outlier correction#
sns.displot(kind='kde',
data=df,
x='rt', hue='flankers')
plt.show()
After outlier correction#
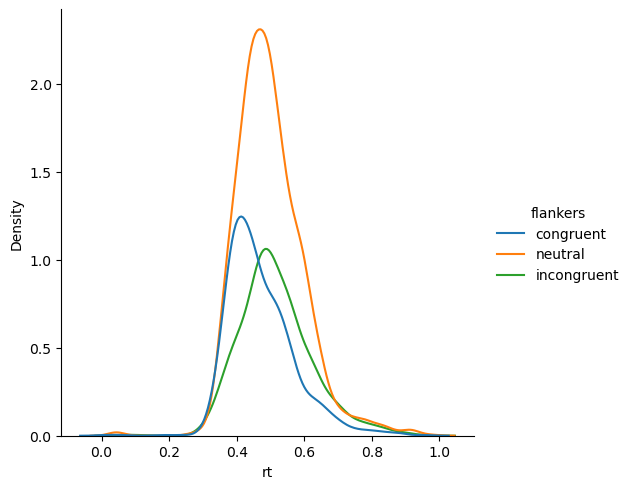
We can see that the distributions look less “peaky” in the middle with long tails. The long tails were caused by the few outlier data points at extreme ends of the 0–1 s range.
sns.displot(kind='kde',
data=df,
x='rt_clean', hue='flankers')
plt.show()