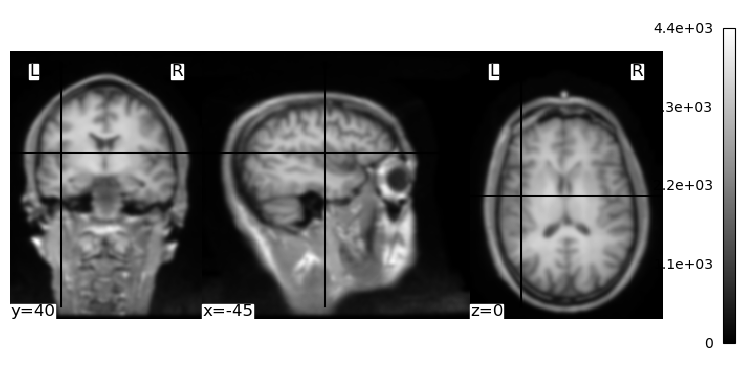
Working with NIfTI images#
NIfTI stands for Neuroimaging Informatics Technology Initiative, which is jointly sponsored by the US National Institute of Mental Health and the National Institute of Neurological Disorders and Stroke. NIfTI defines a file format for neuroimaging data that is meant to meet the needs of the fMRI research community. In particular, NIfTI was developed to support inter-operability of tools and software through a common file format. Prior to NIfTI there were a few major fMRI analysis software packages, and each used a different file format. NIfTI was designed to serve as a common file format for all of these (and future) neuroimaging software packages.
NIfTI was derived from an existing medical image format, called ANALYZE. ANALYZE was originally developed by the Mayo Clinic in the US, and was adopted by several neuroimaging analysis software packages in the 1990s. The ANALYZE header (where meta-data are stored) had extra fields that were not used, and NIfTI format basically expands on ANALYZE by using some of those empty fields to store information relevant to neuroimaging data. In particular the header stores information about the position and orientation of the images. This was a huge issue prior to NIfTI. In particular, there were different standards for how to store the order of the image data. For example, some software packages stored the data in an array that started from the most right, posterior, and inferior voxel, with the three spatial dimensions ordered right-to-left, posterior-to-anterior, and then inferior-to-superior. This is referred to as RPI orientation. Other packages that also used ANALYZE data stored the voxels in RAI format (with the second dimension going anterior-to-posterior) or LPI format (reversing left and right). This caused a lot of problems for researchers, especially if they wanted to try different analysis software, or use a pipeline that involved tools from different software packages. In some cases, this was just annoying (e.g., having to reverse the anterior-posterior dimension of an image). In other cases, it was confounding and potentially created erroneous results. This was especially true of the right-left (x) dimension. While it is immediately obvious when viewing an image which the front and back, and top and bottom, of the brain are, the left and right hemispheres are typically indistinguishable from eahc other, so a left-right swap could easily go undetected, potentially leading researchers to make completely incorrect conclusions about which side of the brain activation occurred on! The NIfTI format was designed to help prevent this by more explicitly storing orientation information in the header.
Another improvement with the NIfTI format was to allow a single file. ANALYZE format requires two files, a header (with a .hdr extension) and the image data itself (.img). These files had to have the same name prior to the extension (e.g., brain_image.hdr and brain_image.img), and doubled the number of files in a directory of images, which created more clutter. NIfTI defines a single image file ending in a .nii extension. As well, NIfTI images can be compressed using a standard, open-source algorithm known as Gzip, which can significantly reduce file sizes and thus the amount of storage required for imaging data. Since neuroimaging data files tend to be large, this compression was an important feature.
Although other file formats are still used by some software, NIfTI has become the most widely used standard for fMRI and other MRI research data file storage. Here we will learn how to convert a DICOM file to NIfTI format, which is typically the first step in an MRI research analysis pipeline, since most MRI scanners produce DICOM files, but the software researchers use to process their data reads NIFTI and not DICOM format.
Import packages#
Here we load in three new Python packages designed to work with NIfTI data:
dicom2nifticonverst DICOM images to NIfTI formatNiBabelreads and converts between NIfTI and several other common neuroimaging file formats, including ANALYZENiLearnis primarily designed to provide statistical analysis and machine learning tools for neuroimaging data. However, it also provides a number of utilities for reading and writing NIfTI images, and working with and visualizing data
As well we’ll load SciPy’s ndimage package, and Matplotlib
import dicom2nifti
import nibabel as nib
import nilearn as nil
import scipy.ndimage as ndi
import matplotlib.pyplot as plt
import os
We will use dicom2nifti’s convert_directory() function to convert the structural MRI images we worked with in the previous lesson from DICOM to NIfTI. We pass it the name of the folder in which the DICOM images are saved, and also instruct it to compress the resulting NIfTI file (to save space). We also use the reorient=True kwarg to force the image to be written in LAI orientation (i.e., starting with the most left, anterior, and inferior voxel), which ensures there is no ambiguity about the resulting NIfTI image.
convert_directory does not take an argument for the output file name. Instead, it uses the name of the scan that was used when it was acquired on the MRI scanner. This might seem like a frustrating lack of control, however it does ensure that there are no user errors in the conversion process, that could result in mis-identified files. Here we will first list the contents of the data folder, then run convert_directory, then list the contents again to see the new NIfTI file and what it is named:
os.listdir('data')
['.DS_Store',
'4_sag_3d_t1_spgr.nii.gz',
'anatomical_aug13_001.hdr',
'Anat001.20040930.145131.5.T1_GRE_3D_AXIAL.0099.dcm',
'anatomical_aug13_001.img',
'DICOM']
dicom2nifti.convert_directory('data/DICOM', 'data', compression=True, reorient=True)
os.listdir('data')
Unable to read: data/DICOM/IM-0004-0159.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0171.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0165.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0039.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0005.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0011.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0010.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0004.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0038.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0164.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0170.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0158.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0166.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0172.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0012.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0006.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0007.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0013.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0173.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0167.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0163.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0177.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0017.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0003.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0002.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0016.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0176.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0162.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0174.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0160.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0148.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0014.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0028.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0029.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0015.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0001.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0149.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0161.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0175.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0112.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0106.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0066.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0072.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0099.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0098.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0073.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0067.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0107.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0113.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0139.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0105.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0111.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0059.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0071.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0065.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0064.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0070.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0058.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0110.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0104.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0138.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0100.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0114.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0128.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0074.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0060.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0048.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0049.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0061.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0075.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0129.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0115.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0101.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0117.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0103.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0063.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0077.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0088.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0089.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0076.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0062.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0102.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0116.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0133.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0127.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0047.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0053.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0084.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0090.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0091.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0085.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0052.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0046.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0126.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0132.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0118.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0124.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0130.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0078.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0050.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0044.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0093.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0087.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0086.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0092.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0045.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0051.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0079.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0131.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0125.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0119.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0121.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0135.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0109.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0055.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0041.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0069.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0096.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0082.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0083.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0097.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0068.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0040.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0054.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0108.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0134.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0120.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0136.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0122.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0042.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0056.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0081.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0095.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0094.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0080.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0057.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0043.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0123.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0137.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0178.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0150.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0144.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0018.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0024.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0030.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0031.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0025.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0019.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0145.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0151.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0179.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0147.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0153.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0184.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0033.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0027.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0026.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0032.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0152.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0146.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0142.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0156.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0181.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0036.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0022.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0023.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0037.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0180.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0157.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0143.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0155.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0141.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0169.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0182.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0021.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0035.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0009.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0008.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0034.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0020.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0183.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0168.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0140.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
Unable to read: data/DICOM/IM-0004-0154.dcm
Traceback (most recent call last):
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/convert_dir.py", line 46, in convert_directory
dicom_headers = compressed_dicom.read_file(file_path,
defer_size="1 KB",
stop_before_pixels=False,
force=dicom2nifti.settings.pydicom_read_force)
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 15, in read_file
if _is_compressed(dicom_file, force):
~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "/Users/aaron/miniforge3/envs/neural_data_science/lib/python3.13/site-packages/dicom2nifti/compressed_dicom.py", line 110, in _is_compressed
header = pydicom.read_file(dicom_file,
^^^^^^^^^^^^^^^^^
AttributeError: module 'pydicom' has no attribute 'read_file'
['.DS_Store',
'4_sag_3d_t1_spgr.nii.gz',
'anatomical_aug13_001.hdr',
'Anat001.20040930.145131.5.T1_GRE_3D_AXIAL.0099.dcm',
'anatomical_aug13_001.img',
'DICOM']
So the new converted file is 4_sag_3d_t1_spgr.nii.gz
Load NIfTI file#
We use NiBabel to read in the NIfTI file we just created:
brain_vol = nib.load('data/4_sag_3d_t1_spgr.nii.gz')
# What is the type of this object?
type(brain_vol)
nibabel.nifti1.Nifti1Image
View metadata#
We can view the image’s header by printing it (note that due to how the NiBabel Nifti1Image object is coded, we need to print() the header rather than just asking for it as a property):
print(brain_vol.header)
<class 'nibabel.nifti1.Nifti1Header'> object, endian='<'
sizeof_hdr : 348
data_type : np.bytes_(b'')
db_name : np.bytes_(b'')
extents : 0
session_error : 0
regular : np.bytes_(b'')
dim_info : 0
dim : [ 3 184 256 256 1 1 1 1]
intent_p1 : 0.0
intent_p2 : 0.0
intent_p3 : 0.0
intent_code : none
datatype : int16
bitpix : 16
slice_start : 0
pixdim : [-1. 1. 1. 1. 1. 1. 1. 1.]
vox_offset : 0.0
scl_slope : nan
scl_inter : nan
slice_end : 0
slice_code : unknown
xyzt_units : 2
cal_max : 0.0
cal_min : 0.0
slice_duration : 0.0
toffset : 0.0
glmax : 0
glmin : 0
descrip : np.bytes_(b'')
aux_file : np.bytes_(b'')
qform_code : unknown
sform_code : aligned
quatern_b : 0.0
quatern_c : 1.0
quatern_d : 0.0
qoffset_x : 89.6006
qoffset_y : -76.964
qoffset_z : -157.9353
srow_x : [-1. -0. -0. 89.6006]
srow_y : [ 0. 1. -0. -76.964]
srow_z : [ -0. -0. 1. -157.9353]
intent_name : np.bytes_(b'')
magic : np.bytes_(b'n+1')
Access data in the NIfTI object#
NiBabel’s handling of the NIfTI format data is not quite as elegant as what we saw in the previous lesson. Rather than being able to access the data directly by referencing the name of the object (in this case, brain_vol), we need to use the method get_fdata() to do this (the “f” in this method name stands for “floating point”, as this is the type of data it returns). We will assign the result of this to a new variable so that it’s easy to work with.
brain_vol_data = brain_vol.get_fdata()
type(brain_vol_data)
numpy.ndarray
We see that the data is a familiar NumPy array, and below we see the dimensions are identical to what we saw for this image in the previous lesson:
brain_vol_data.shape
(184, 256, 256)
Visualize a slice#
We can use .plt.imshow() as in the previous lesson:
plt.imshow(brain_vol_data[96], cmap='bone')
plt.axis('off')
plt.show()
Note that our image is rotated, so use can use ndi.rotate to fix this:
plt.imshow(ndi.rotate(brain_vol_data[96], 90), cmap='bone')
plt.axis('off')
plt.show()
Plot a series of slices#
fig_rows = 4
fig_cols = 4
n_subplots = fig_rows * fig_cols
n_slice = brain_vol_data.shape[0]
step_size = n_slice // n_subplots
plot_range = n_subplots * step_size
start_stop = int((n_slice - plot_range) / 2)
fig, axs = plt.subplots(fig_rows, fig_cols, figsize=[10, 10])
for idx, img in enumerate(range(start_stop, plot_range, step_size)):
axs.flat[idx].imshow(ndi.rotate(brain_vol_data[img, :, :], 90), cmap='gray')
axs.flat[idx].axis('off')
plt.tight_layout()
plt.show()
Plot with NiLearn#
While SciPy’s ndimage module was designed for working with a wide variety of image types, NiLearn was designed to work with neuroimaging data specifically. As such, it’s tools are a bit easier to use and more purpose-built for tasks that neuroimaging data scientists might want to perform. For example, we can plot the NiBabel NIfTI image object directly without first having to extract the data, using the plot_img() function from NiLearn’s plotting module:
from nilearn import plotting
plotting.plot_img(brain_vol)
plt.show()
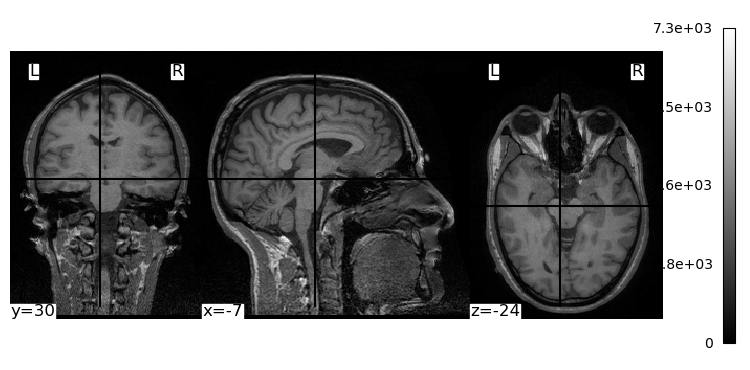
One nice thing that we see is that since NiLearn is neuroimaging-aware, it explicitly adds labels to our plot showing us clearly which the left and right hemispheres are.
NiLearn’s plotting library uses Matplotlib, so we can use familiar tricks to do things like adjust the image size and colormap:
from nilearn import plotting
fig, ax = plt.subplots(figsize=[10, 5])
plotting.plot_img(brain_vol, cmap='gray', axes=ax)
plt.show()
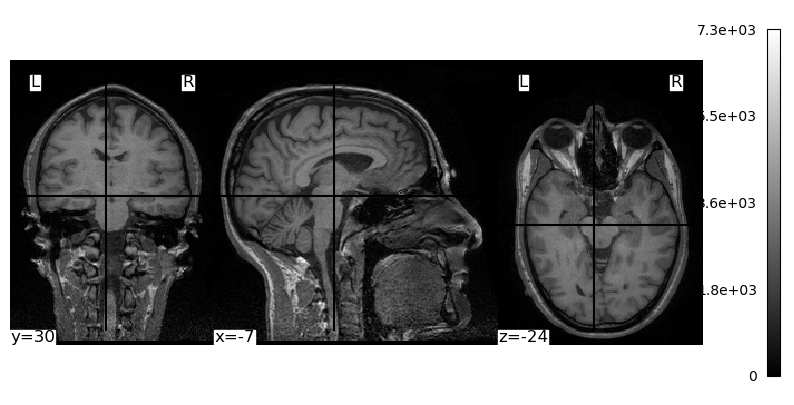
The plot_img() function also provides a variety of ways to display the brain, with much less code than we had to use when working with raw NumPy arrays and Matplotlib functions:
plotting.plot_img(brain_vol, display_mode='tiled', cmap='gray')
plt.show()
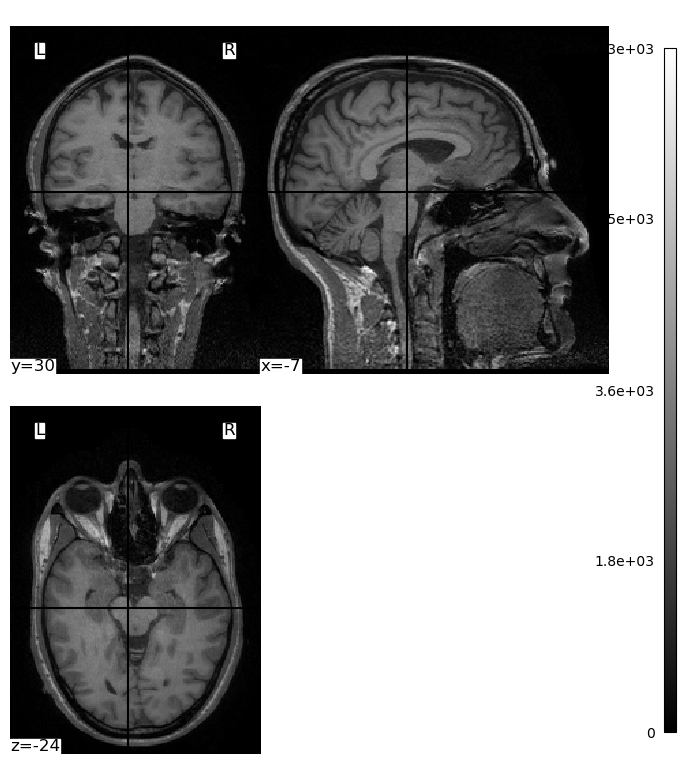
We can use the cut_coords kwarg to specify there to centre the crosshairs and “cuts” through the image that we visualize. In this image, the coordinates are relative to the *isocenter of the MRI scanner — the centre of the magnetic field inside the scanner. The position of a person’s head relative to this isocenter will vary from individual to individual, and scan to scan, due to variations in head size and the optimizations used by the MRI technician and scanner. But we can use the coordinates printed in the above image (which defaulted to the centre of the image volume) and some trial-and-error to get a different view through the brain:
plotting.plot_img(brain_vol, cmap='gray', cut_coords=(-45, 40, 0))
plt.show()
plot_img() also has a few other ways to see multiple slices at once:
plotting.plot_img(brain_vol, display_mode='x', cmap='gray')
plt.show()

plotting.plot_img(brain_vol, display_mode='mosaic', cmap='gray')
plt.show()
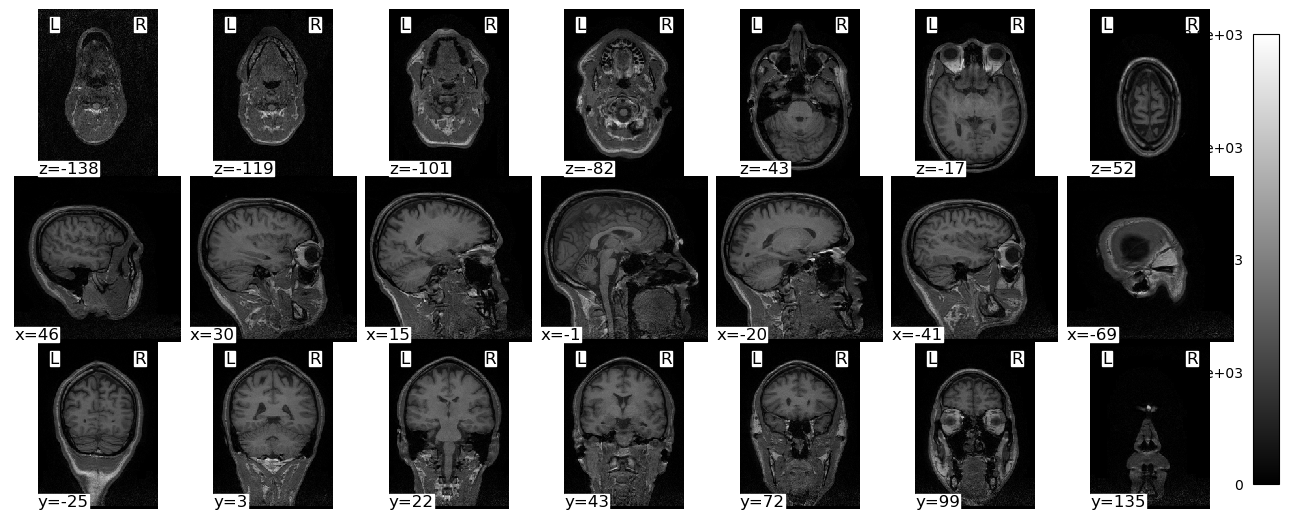
Smoothing#
NiLearn has its own function for applying Gaussian spatial smoothing to images as well. The only real difference from scipy.ndimage’s gaussian_filter() function is that instead of specifying the smoothing kernel in standard deviations, we specify it in units of full width half-maximum (FWHM). This is the standard way that most neuroimaging analysis packages specify smoothing kernel size, so it is preferable to SciPy’s approach. As the term implies, FWHM is the width of the smoothing kernel, in millimetres, at the point in the kernel where it is half of its maximum height. Thus a larger FWHM value applies more smoothing.
from nilearn import image
fwhm = 4
brain_vol_smth = image.smooth_img(brain_vol, fwhm)
plotting.plot_img(brain_vol_smth, cmap='gray', cut_coords=(-45, 40, 0))
plt.show()